From texts to exercises (semi)automatically
Neven Jovanović (neven.jovanovic@ffzg.hr)
Berlin, October 4-5, 2017
This page: croala.ffzg.unizg.hr/callidus-automatic-exercises/
Repository: bitbucket.org/nevenjovanovic/discipulus
The Plan
Preliminary thoughts
The components
Case study: exercises for a reading corpus
What is missing?
Preliminary
The role: supplement and preparation
Which types of exercises?
The force of images, sound, actions
The prototype issue
The components
1. The texts
"Here are the texts I want, or need, to read — can you help me read them?"
2. Grammatical annotations
3. Vocabularies
(... auf Deutsch?)
4. Manipulation
BaseX and XQuery
CLTK and Python
5. Publication
Moodle: more control to the teacher
H5P: works with Moodle, excellent design
Anki: more control to the learner
Both Moodle and Anki are accessible
from smartphones as well!
From texts to a reading corpus
Many small steps...
the texts, tokenized into
chapters
sentences
phrases
words
frequencies
for the whole corpus
for texts
for chapters
(even for sentences?)
lemmata for tokens
connect lemmata with tokens!
frequencies for lemmata
concentrate on what is frequent — or on what is rare!
alignments of translations...
with lemmata
with occurrences
with phrases
with sentences
distractors for multiple choice etc.
sound...? video...?
(Cf. the Memrise "Meet the natives" feature.)
Case study: reading list for the "Translation from Latin" course at the University of Zagreb
Seneca, Letters to Lucilius 1
Terence, Adelphoe
Horace, Odes 1
Tibullus 1
Compile the corpus
Get the texts from the Perseus DL
All texts are available there, but the task was not quite trivial, because we needed just some segments (some books) of these works, and also — as it turns out — because the texts contain critical notes and, in two places, funny division of words (Horatian metres!).
Create word lists and frequencies
The corpus contains 24,318 words.
Seneca: 6272
Terence: 8874
Horace: 3967
Tibullus: 5211
Feed the word list to LEMLAT for lemmatization analysis.
The results:
Number of word forms: 8548 (different forms in 24,318 words)
Number of forms unknown to the program: 103
Number of forms analysed: 8445
Annotate LEMLAT analyses
for single or multiple candidates
Distinguish forms with multiple candidate lemmata (multilem) from the forms with unambiguous lemmata
(both derived and unique).
Some LEMLAT lemmata are homonyms, or even identical, though they have different LEMLAT id numbers;
if we isolate such cases, the number of annotated forms can be enlarged further.
An opportunity to engage students?
Tokenize the texts into sentences and words
For sentences, CLTK has the best tool; we want to use the tool through a pair of Python scripts:
one which reads all text files, the other which tokenizes the text in them into sentences.
(We also need to prepare text-only versions of our segments.)
Then we reconstruct from JSON files (output by the CLTK tool) the text documents, with all their chapters, scenes, letters, and poems, but now also with sentences below these levels (and tokenized into words and punctuation as well).
For that, we have two XQuery scripts: one to annotate punctuation, the other to tokenize the remaining text nodes.
Annotate word forms in corpus with pointers to LEMLAT lemmata
<w lemma="homo" lemmaRef="lemlat:h234">hominem</w>
Automatically, a little over 48% of words in the corpus is lemmatized.
Create exercises
Anki
Practise vocabulary and sentences
{{c1::crastinum::sutrašnji dan}} si adiecerit deus, laeti recipiamus. cras
{{c1::crastinum::sutrašnji dan}} sine sollicitudine expectat. cras
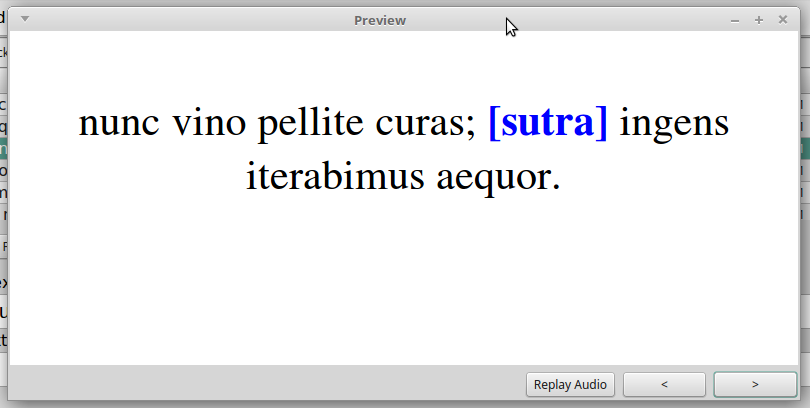
{{c1::cras::sutra}} ingens iterabimus aequor. cras
nunc vino pellite curas; {{c1::cras::sutra}} ingens iterabimus aequor. cras


Interesting exercise types
Latin word / Croatian meaning and reverse
(to introduce a word)
Sentence with a Croatian translation, and reverse
Cloze card with the word to be supplied in Croatian
(in its vocabulary form)
Smaller, meaningful phrases from sentences
with translation and clozes
Croatian words in vocabulary form, ordered as in the sentence (produce the correct sentence in Latin!)
Moodle — Database activity
Add translations
Omega (= Moodle instance of the Faculty of Humanities and Social Sciences, University of Zagreb)
Moodle — Question bank
Mass import of automatically generated Q&A cards